بخش قبلی مطلب مرتبط با علم داده کاوی را در این آدرس مطالعه کنید.
علم داده کاوی از جمله حوزههای فناوری اطلاعات است که از زمان پیدایش تا به امروز سریعترین رشد را داشته است. زمانیکه متخصصان علم اقتصاد و کامپیوتر دریافتند که امکان بهکارگیری محاسبات آماری و ریاضی به شیوهای نوین در حوزه علوم کامپیوتر فراهم است، به سرعت دست بهکار شدند و علم نوینی که امروزه بهنام علم داده کاوی میشناسیم را پایهگذاری کردند.
یکی از بزرگترین نقاط قوت داده کاوی ارائه طیف گستردهای از روشها و تکنیکهایی است که میتواند برای حل مجموعهای از مشکلات به کار گرفته شود. از آنجایی که داده کاوی یک فعالیت عادی است که باید روی مجموعهای بزرگ از دادهها انجام شود، انبارههای داده و بانکهای اطلاعاتی رابطهای و غیر رابطهای اصلیترین مخاطبان این حوزه هستند.
در دنیای تجارت از دادهکاوی میتوان برای شناسایی ترندهای جدید خرید، هوش تجاری، برنامهریزی راهبردی سرمایهگذاری و شناسایی هزینههای غیر ضروری در بخش حسابداری استفاده کرد. رویکرد فوق میتواند کمپینهای بازاریابی را بهبود بخشد و از نتایج بهدست آمده برای پشتیبانی مطلوبتر از مشتریان استفاده کند.
علاوه بر این، تکنیکهای دادهکاوی را میتوان برای برطرف کردن مشکلات مهندسی مجدد فرآیندهای کسبوکار که هدف درک بهتر تعاملات و ارتباط میان شیوههای تجاری و راهبردهای سازمانی است، به کار گرفت.
پیشنهاد مقاله: چرا آموزش داده کاوی مهم است؟
آمارها نشان میدهند که بسیاری از نهادهای قانونی و تحقیقاتی که ماموریت آنها شناسایی فعالیتهای متقلبانه و کشف جرم است با استفاده از دادهکاوی به موفقیتهای بزرگی رسیدهاند. بهطور مثال، این روشها میتوانند به تحلیلگران در شناسایی الگوهای رفتاری مهم، شناسایی ارتباط میان باندهای خرابکار سازمانیافته، شناسایی معاملاتی که با هدف پولشویی انجام میشوند و گردشهای مالی که توسط شرکتهایی که وجود خارجی ندارند کمک کنند.
علاوه بر این، تکنیکهای دادهکاوی این ظرفیت را دارند تا توسط افراد شاغل در نهادهای دولتی که دسترسی به منابع بزرگی از دادهها دارند به کار گرفته شود تا هرگونه فعالیت مشکوکی که مرتبط با مسائل امنیت ملی است به سرعت شناسایی شود. در حالی که سازمانهای بزرگ نسبت به پیادهسازی سنتی استراتژیهایی دارند که به اشتباه تدوین میشوند، علاقهای افراطگونه دارند؛ در نقطه مقابل، دادهکاوی این ظرفیت را دارد که با ارائه عملکردی پایدار به سازمانها در تدوین استراتژیهای کارآمد کمک کند. فراموش نکنید که دادهکاوی برای استفاده عملی در دنیای تجارت، تکامل یافته و سازگار شده است.
مبدا پیدایش علم داده کاوی
اگر به تعاریف ارائه شده توسط نویسندگان مختلف در خصوص دادهکاوی نگاهی داشته باشیم، مشخص میشود که هنوز دیدگاه جامع و مشخصی در ارتباط با تعریف دادهکاوی یا آنچه بهنام دادهکاوی وجود دارد ارائه نشده است.
آیا دادهکاوی تلفیق محاسبات آماری با تئوریهای یادگیری غنی است یا یک تحول بنیادین بزرگ است؟ به عقیده اینجانب، اکثر راهحلها و تکنیکهایی که توسط دادهکاوی ارائه میشوند، ریشه در تحلیل دادههای کلاسیک دارند. مباحث آماری و یادگیری ماشین، دو علم کاملا تاثیرگذار بر علم داده کاوی هستند.
مباحث آماری ریشه در ریاضیات دارند و بنابراین از منطق سختگیرانه ریاضیات پیروی میکنند و بر این نکته تاکید دارد که هر مفهومی قبل از آنکه به شکل عملی آزمایش شود باید به لحاظ نظری معقول باشد. در نقطه مقابل، مبدا شکلگیری یادگیری ماشین، در علوم کاربردی و عملی کامپیوتری است و به این فلسفه تمایل دارد که قبل از آنکه هر مفهومی به شکل رسمی به اثبات برسد باید آزمایشی شود تا میزان کارکرد آن مفهوم بهدست آید.
اگر جایگاه ریاضیات و قانونمندسازی یا به عبارت دقیقتر انطباق علوم با نظریههای اثبات شده یکی از تفاوتهای عمده میان رویکردهای آماری و یادگیری ماشین در مبحث دادهکاوی باشد، تفاوت دیگر آنها در تأکید نسبی مدلها و الگوریتمها است. مباحث آماری مدرن تقریباً متاثر از مفهوم مدل هستند. این یک ساختار فرضی است یا یک تقریب ساختاری است که میتواند منجر به شکلگیری دادهها شود.
یادگیری ماشین به جای تأکید آماری روی مدلها، به تأکید بر الگوریتمها تمایل دارد. البته این موضوع چندان هم عجیب نیست. واژه “یادگیری” در برگیرنده مفهومی است که به یک الگوریتم ضمنی اشاره دارد.
اصول اساسی مدلسازی در دادهکاوی، در نظریه کنترل ریشه دارند که جایگاه مشخص و تعریف شدهای در سامانههای مهندسی و فرآیندهای صنعتی دارد. در این روش تعیین مدل ریاضی برای یک سامانه ناشناخته (که بهنام سامانه هدف شهرت دارد) با مشاهده جفت دادههای ورودی و خروجی که بهطور کلی به عنوان متغیرهای شناسایی سامانه معروف هستند انجام میشود.
این فرآیند به دلایل مختلفی انجام میشود، با اینحال از نقطه نظر دادهکاوی، شناسایی سیستم با هدف پیشبینی رفتار سامانه و توضیح تعامل و روابط میان متغیرهای یک سیستم انجام میشود. شناسایی سیستم بهطور کلی از دو مرحله بالا به پایین به شرح زیر انجام میشود:
شناسایی ساختار (Structure identification) – در این مرحله، باید از دانش قبلی موجود در مورد سیستم برای تعیین گروهی از مدلهای واجد شرایط استفاده کنیم و در ادامه به جستوجوی مناسبترین مدل باشیم. بهطور معمول، این کلاس از مدلها با یک تابع پارامتری به شرح زیر نشان داده میشوند.
y= f(u,t)
جایی که y خروجی مدل است، u یک بردار ورودی است و t یک بردار پارامتری است. تعیین عملکرد تابع f وابسته به مشکل است و عملکرد تابع بر اساس تجربه، اطلاعات شهودی و قوانین طبیعی حاکم بر سیستم هدف ارزیابی میشود.
شناسایی پارامتر (Parameter identification)– در مرحله دوم، هنگامی که ساختار مدل مشخص شد، تنها کاری که باید انجام دهیم این است که از تکنیکهای بهینهسازی برای تعیین بردار پارامتر t استفاده کنیم، بهطوری که خروجی تابع زیر میتواند سامانه مناسب را توصیف کند.
y*=f(u,t*)
بهطور کلی، شناسایی سیستم را نباید یک فرآیند تک مرحلهای در نظر بگیریم، زیرا هر دو مرحله شناسایی ساختار و شناسایی پارامتر باید به دفعات انجام شوند تا زمانیکه مدل رضایت بخشی پیدا شود. شکل زیر این فرآیند تکرارشونده را نشان میدهد.
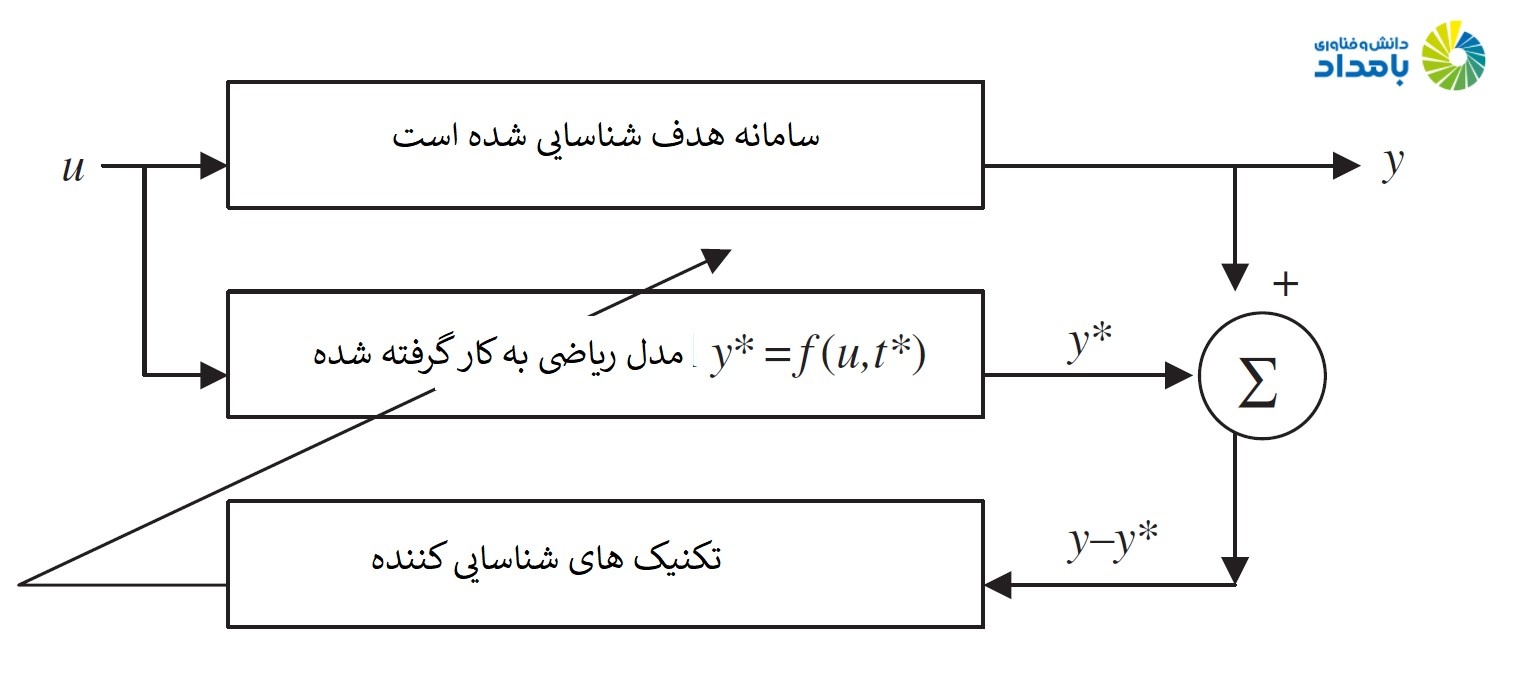
فرآیند شناسایی سیستم با استفاده از چرخه تکراری انجام میشود تا در نهایت، نتایج مدنظر متخصصان را ارائه کند.
مراحلی که بهطور معمول در هر تکرار انجام میشوند به شرح زیر است:
1. كلاسی از مدلهای رسمی (ریاضی) را باید مشخص و پارامتری کرد که نمایانگر سیستمی است که باید شناسایی شود. برای این منظور از فرمول زیر استفاده میشود.
y*=f(u,t)
2. برای انتخاب مولفههایی که با مجموعه دادههای موجود به بهترین وجه، اشتراک دارند، لازم است فرآیند شناسایی پارامتر انجام شود. (در این حالت تفاضل y-y* کمینه را نشان میدهد).
3. لازم است از آزمونهای اعتبارسنجی برای بررسی این موضوع استفاده کرد که آیا مدل شناسایی شده به مجموعه دادههای غیر نمایان واکنش درستی نشان میدهد (این آزمون بهنام اعتبارسنجی یا بررسی مجموعه دادهها معروف است).
4. اگر نتایج بهدست آمده از آزمون رضایتبخش بود، فرآیند را خاتمه دهید.
در شماره آینده مبحث فوق را ادامه میدهیم.
نویسنده: حمیدرضا تائبی