بعد از آشنایی با مفاهیم مهم دادهکاوی در مقالات شماره قبل، اکنون قصد داریم برای درک بهتر مفاهیم داده کاوی به سراغ دو پروژه کاربردی در این زمینه برویم. ابتدا فرایند ساخت مدل رگرسیون را بررسی میکنیم.
پیشنهاد مقاله: چگونه از پایتون برای داده کاوی استفاده کنیم؟
ساخت یک مدل رگرسیون با پایتون
برای ساخت یک مدل رگرسیون، باید هدفی را مشخص کنیم. هدف در این مقاله آموزش داده کاوی با پایتون به منظور بهدست آوردن یک برآورد (تخمین از رابطه خطی بین متغیرها و چاپ ضریبهای همبستگی (Coefficients Of Correlation) و ترسیم یک خط است که بهترین برازش (تناسب) را ایجاد کند.
برای تحلیل این پروژه از مجموعه داده King’s County استفاده میشود که بهشکل رایگان از سایت Kaggle قابل دریافت است. Kaggle یک منبع فوقالعاده برای دانلود مجموعه دادههای مختلف است که افراد میتوانند این مجموعه دادهها را در پروژههای علم داده به کار گیرند. مجموعه دادههای King’s County اطلاعاتی فرضی در مورد قیمت مسکن و ویژگیهای آنها است. در این پروژه آموزشی نحوه بهدست آوردن برآورد رابطه میان قیمت مسکن و اندازه خانه (مساحت بر حسب فوت مربع) بررسی میشود.
گام اول: نصب ابزارهای داده کاوی برای ساخت مدل رگرسیون
در اولین گام باید نرمافزار Jupyter را نصب کنیم. Jupyter Notebook یک نرمافزار وبمحور متن باز است که با استفاده از آن میتوان اسنادی که شامل کدهای آنلاین (Live Code)، معادلهها، تصویرسازی و متن هستند را ایجاد کرده و به اشتراک گذاشت. به بیان دقیقتر، ژوپیتر یک زیرساخت رایگان است که از طریق آن یک پردازنده برای نوتبوکهای iPython برای اجرای فایلهای .ipynb در اختیارتان قرار میگیرد.
با توجه به اینکه کدنویسی در ژوپیتر بصری است، افراد برای شروع کار با پروژههای علم داده آنرا نصب و استفاده میکنند. برای نصب پلتفرم Jupyter نیازی به کدنویسی نیست، زیرا در توزیع پایتون آناکوندا (Anaconda Python Distribution)، نوتبوک ژوپیتر و بستههای رایج و کاربردی علم داده و محاسبات علمی وجود دارند. به همین دلیل با استفاده از توزیع پایتون آناکوندا امکان استفاده از Jupyter فراهم میشود. برای اجرای نوتبوک Jupyter دستور زیر را اجرا کنید:
jupyter notebook
علاوه بر استفاده از توزیع پایتون Anaconda، میتوان با دستور زیر نیز نوتبوک Jupyter را روی سیستم خود نصب کرد، اما قبل از نصب باید جدیدترین نسخه از سیستم مدیریت بسته Pip روی سیستم وجود داشته باشد. برای اطمینان از بهروز بودن Pip دستور زیر را اجرا کنید:
pip3 install –upgrade pip
با اجرای دستور فوق جدیدترین نسخه بسته مدیریت منیجر Pip نصب میشود. اکنون میتوان با استفاده از دستور زیر نوتبوک ژوپیتر را نصب کنید:
pip3 install jupyter
در مرحله بعد باید به سراغ ساخت مدل رگرسیون برویم. دقت کنید در اینجا تمام کدهای پروژه در مسیر فایل Python [Root] در ژوپیتر اجرا میشوند. از ماژول Pandas در پایتون برای تمیزسازی دادهها (Data Cleaning) و ساختاردهی دوباره آنها استفاده میشود.
Pandas یک ماژول متن باز برای کار با ساختمان دادهها و تحلیل آنها است. Pandas یکی از مهمترین و کاربردیترین ابزارهای در دسترس متخصصان علم دادهها است که امکان استفاده از آن در پایتون وجود دارد. Pandas به گونهای طراحی شده است که یک زیرساخت ساده و مناسب برای مدیریت، مرتبسازی و دستکاری دادهها ارایه میکند.
دانشمندان علم داده با کمک Pandas میتوانند دادهها را با هر فرمتی بارگذاری کنند. اکنون باید تمام ماژولهای ضروری و پراهمیت به محیط Jupyter اضافه شوند. با استفاده از دستورات زیر کتابخانههایی مانند Numpy ،Pandas ،Scikit-learn و Matplotlib به پروژه اضافه میشوند:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import seaborn as sns
from matplotlib import rcParams
%matplotlib inline
%pylab inline
Populating the interactive namespace from numpy and matplotlib
اکنون که مقدمات اولیه را آماده کردیم، باید نحوه استفاده از داده کاوی در حل مسئله رگرسیون را بررسی کنیم. در اینجا سعی میکنیم، مطالب را بهزبانی ساده شرح دهیم. بهطور معمول، مجموعه دادههایی که در جهان واقعی وجود دارند بهطور خودکار برای پیادهسازی تکنیکهای یادگیری ماشین آماده نیستند و باید فرایند پاکسازی و سازماندهی روی آنها انجام داد. برای خواندن فایل حاوی مجموعه دادهها از Kaggle با استفاده از کتابخانه Pandas، از دستور زیر استفاده میشود:
df = pd.read_csv(‘/Users/michaelrundell/Desktop/kc_house_data.csv’)
df.head()
در دستور فوق با کمک pd.read_csv امکان خواندن فایل CSV توسط Pandas فراهم شده است. خروجی کدهای فوق در ادامه آمده است:
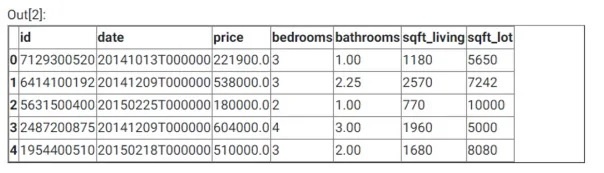
خواندن فایل CSV از Kaggle با به کارگیری Pandas
در خط دوم دستورات فوق از فرمان df.head() برای نمایش پنج سطر اول مجموعه داده استفاده شده است. df.head() یک تابع کاربردی از کتابخانه Pandas است. اکنون باید بررسی کنیم که آیا مجموعه دادهها دارای مقادیر تهی هستند یا خیر؟ اگر پاسخ مثبت است، باید حذف شوند، زیرا تاثیری روی عملکرد مدل ندارند. برای بررسی وجود مقادیر تهی در مجموعه دادهها باید از دستور زیر استفاده کرد:
df.isnull().any()
خروجی دستور بالا به شکل زیر نشان داده میشود. این خروجی نشان میدهد که مقادیر تهی در مجموعه دادهها وجود ندارند:

خروجی حاصل از بررسی وجود مقادیر تهی در دادهها
همچنین، با استفاده از دستور زیر، میتوان نوع متغیرهای پروژه را مشاهده کرد:
df.dtypes
در ادامه، خروجی دستور فوق قابل مشاهده است: 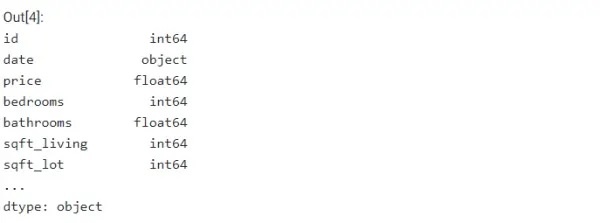 پرسشی که مطرح میشود این است که چرا نوع متغیرهای پروژه مهم است؟ به دلیل اینکه برای ادامه دادن مسیر آموزش داده کاوی با پایتون، دانستن اینکه کدام دادهها عددی و کدام یک از نوع شی هستند، ضروری است.
پرسشی که مطرح میشود این است که چرا نوع متغیرهای پروژه مهم است؟ به دلیل اینکه برای ادامه دادن مسیر آموزش داده کاوی با پایتون، دانستن اینکه کدام دادهها عددی و کدام یک از نوع شی هستند، ضروری است.
اکنون که نکات پایه آموزش داده کاوی را بررسی کردیم، برای اینکه آموزش داده کاوی با پایتون بهطور جامع و اصولی انجام شود، بهشکل فهرستوار کارهایی که برای ساخت مدل رگرسیون انجام دادیم را بررسی میکنیم.
مرحله اول با ساخت مدل با استفاده از Pandas، وارد کردن (Import) و خواندن دیتافریم از CSV انجام شد. در ادامه با استفاده از تابع isnull() بررسی شد که آیا تمام دادهها برای مسئله رگرسیون قابل استفاده هستند یا خیر (آیا مقادیر تهی در مجموعه دادهها وجود دارد یا خیر)؟
در پروژههای واقعی، ممکن است یک ستون، دادههایی به شکل اعداد صحیح، رشتهها یا NaN داشته باشد و همه آنها در یک مکان باشند. به همین دلیل باید قبل از ساخت مدل رگرسیون با این مجموعه دادهها، تطابق نوعها و مناسب بودن آنها برای مسئله رگرسیون بررسی شود.
مجموعه دادههایی که برای پروژههای ارائه شده در این مقاله استفاده شدهاند پالایش شده هستند و مشکلی خاصی در ارتباط با آنها وجود ندارد، اما در دنیای واقعی انجام اینکار ضروری است.
گام دوم: تحلیل اکتشافی ساده و نتایج رگرسیون
ابتدا باید مفهوم دادهها را بررسی کنیم. شکل دادهها در دادهکاوی اهمیت زیادی دارد و باید در پروژهها از دادههایی استفاده شود که قالب درستی دارند. وجود دادههای مخدوش یا آسیبدیده (Corrupted) از رایجترین مشکلات پروژههای علم داده است، بنابراین در هنگام کار روی این پروژهها باید به دو نکته مهم زیر دقت کنید:
مشاهده تمام متغیرهای داخل پروژه تجزیه و تحلیل با استفاده از تابع df.describe() به کارگیری plt.pyplot.hist() برای ساخت هسیتوگرامهای (Histograms) متغیرهایی که نقش کلیدی در پروژه دارند.
لازم به توضیح است که هسیتوگرام، نمودار ستونی برای نمایش دادههای مرتبط به هم است که عمدتا در مبحث آمار و احتمالات برای نشان دادن تخمین از آنها استفاده میشود. در ادامه، این کدها و خروجی آنها نمایش داده شدهاند. دستور زیر برای نمایش متغیرهای تحلیلی استفاده میشود:
df.describe()
خروجی دستور فوق به صورت زیر است: 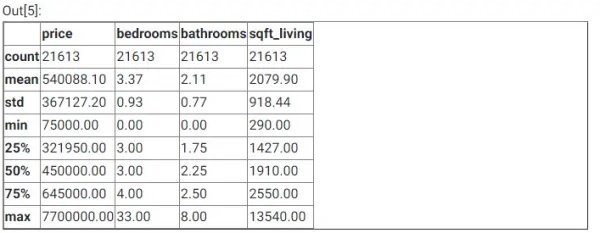 اگر به تصویر فوق دقت کنید مشاهده میکنید که تعداد مجموعه دادههای مشاهده شده در این پروژه 21,613، قیمت میانگین تقریباً 540 هزار دلار، قیمت میانه تقریباً ۴۵۰ هزار دلار و میانگین فضای خانه تقریباً ۱۹۳ مترمربع است.
اگر به تصویر فوق دقت کنید مشاهده میکنید که تعداد مجموعه دادههای مشاهده شده در این پروژه 21,613، قیمت میانگین تقریباً 540 هزار دلار، قیمت میانه تقریباً ۴۵۰ هزار دلار و میانگین فضای خانه تقریباً ۱۹۳ مترمربع است.
اکنون باید با استفاده از کتابخانه Matplotlib دو هیستوگرام چاپ شود که با کمک آنها نحوه توزیع قیمت مسکن و اندازه آنها بر حسب فوت مربع قابل مشاهده باشد. دستور زیر برای ساخت هیستوگرام استفاده میشود:
fig = plt.figure(figsize=(12, 6))
sqft = fig.add_subplot(121)
cost = fig.add_subplot(122)
sqft.hist(df.sqft_living, bins=80)
sqft.set_xlabel(‘Ft^2’)
sqft.set_title(“Histogram of House Square Footage”)
cost.hist(df.price, bins=80)
cost.set_xlabel(‘Price ($)’)
cost.set_title(“Histogram of Housing Prices”)
plt.show()
خروجی قطعه کد فوق به صورت زیر است: 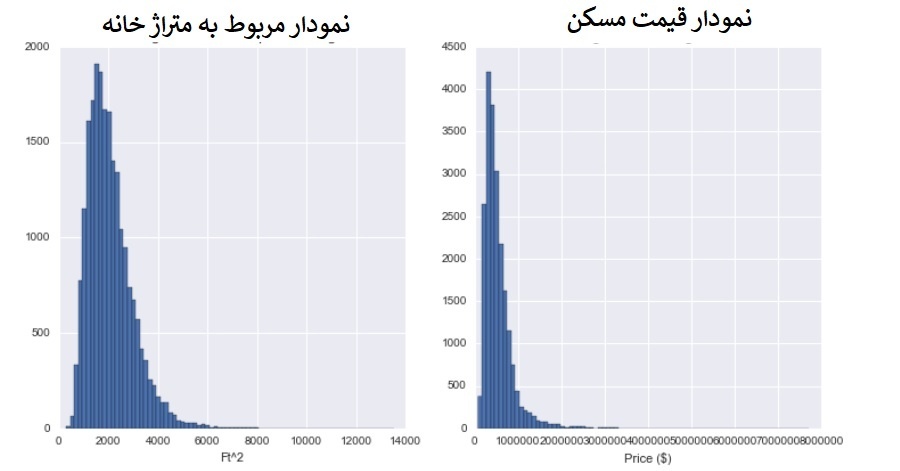 با مشاهده هیستوگرامهای قیمت مسکن و اندازه مسکن، متوجه میشویم که هر دو متغیر به سمت راست متمایل شدهاند. تا این مرحله دید کلی از مجموعه دادهها بهدست آوردیم و نحوه توزیع متغیرهایی که باید ارزیابی شوند را بررسی کردیم. اکنون باید تحلیل رگرسیون را انجام دهیم ابتدا باید ماژول statsmodels پایتون را برای استفاده از تابع تخمین رگرسیون حداقل مربعات به پروژه وارد (Import) کنیم. بیشتر عملیات مربوط به فرآیندهای عددی رگرسیون در پایتون با استفاده از ماژول حداقل مربعات معمولی (Ordinary Least Squares) که OLS نام دارد، انجام میشود. دستور زیر برای وارد کردن ماژول statsmodels و OLS استفاده میشود:
با مشاهده هیستوگرامهای قیمت مسکن و اندازه مسکن، متوجه میشویم که هر دو متغیر به سمت راست متمایل شدهاند. تا این مرحله دید کلی از مجموعه دادهها بهدست آوردیم و نحوه توزیع متغیرهایی که باید ارزیابی شوند را بررسی کردیم. اکنون باید تحلیل رگرسیون را انجام دهیم ابتدا باید ماژول statsmodels پایتون را برای استفاده از تابع تخمین رگرسیون حداقل مربعات به پروژه وارد (Import) کنیم. بیشتر عملیات مربوط به فرآیندهای عددی رگرسیون در پایتون با استفاده از ماژول حداقل مربعات معمولی (Ordinary Least Squares) که OLS نام دارد، انجام میشود. دستور زیر برای وارد کردن ماژول statsmodels و OLS استفاده میشود:
import statsmodels.api as sm
from statsmodels.formula.api import ols
هنگامی که با کمک OLS، کدهای تولید خلاصه برای یک رگرسیون خطی با تنها دو متغیر نوشته میشوند، فرمول زیر استفاده میشود:
Reg = ols(‘Dependent variable ~ independent variable(s), dataframe).fit()
print(Reg.summary())
اکنون برای مشاهده گزارش خلاصه قیمت مسکن و ابعاد آنها باید از دستورات زیر استفاده کنیم:
m = ols(‘price ~ sqft_living’,df).fit()
print (m.summary())
در ادامه، خروجی مربوط به خلاصه یک مدل رگرسیون ساده را مشاهده میکنیم. 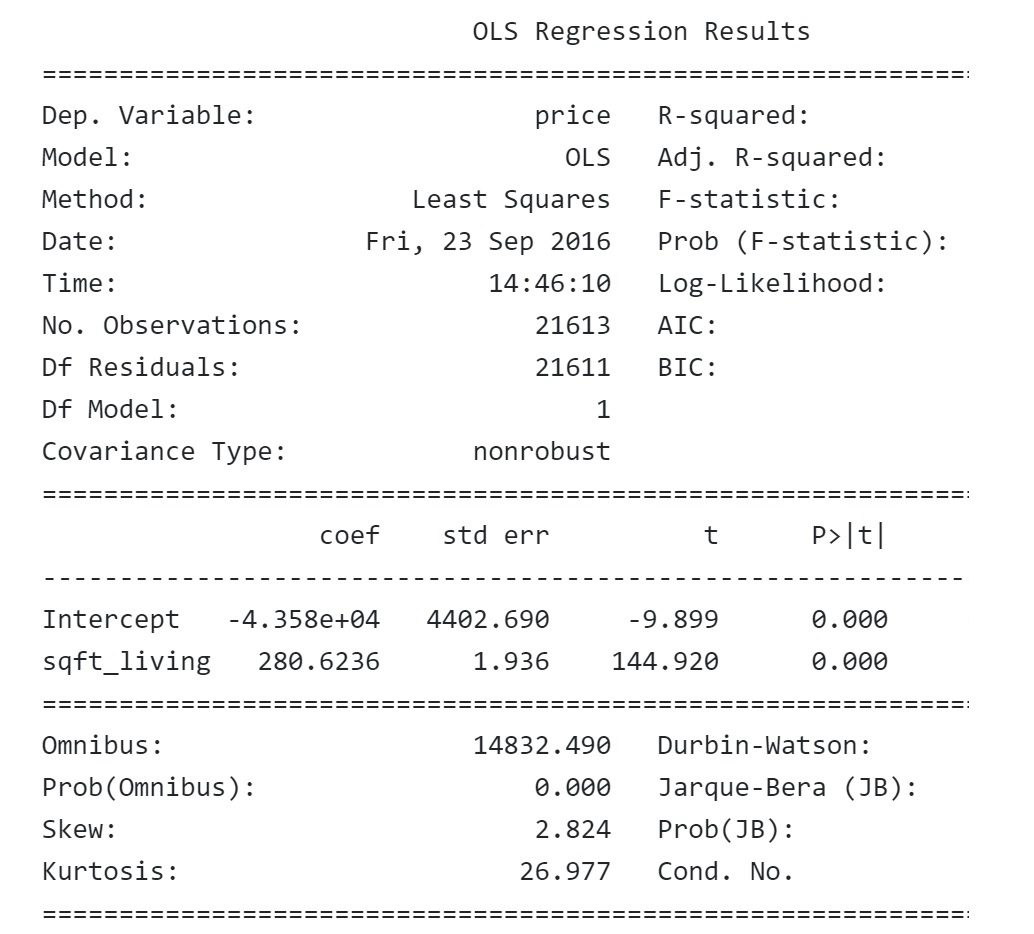 اگر مشابه بالا خلاصه کمترین مربعات معمولی رگرسیون چاپ شود، میتوان اطلاعات مرتبط و متناسب نیاز را دریافت کرد. با نگاه به خروجی، روشن است که بین مساحت خانه و قیمت مسکن رابطه مستقیمی وجود دارد. بهطوری که مقدار t-value بسیار بالا (144.920) و |P>|t صفر درصد است. این یعنی، احتمال اینکه رابطه میان قیمت مسکن و مساحت مسکن شانسی یا به دلیل تغییرات آماری باشد تقریباً صفر است. بهعلاوه، ارتباط میان قیمت مسکن و اندازه آن یک رابطه با اندازه و بزرگی (Magnitude) مناسب است، بهگونهای که به ازای هر 100 فوت مربع اضافه شده به وسعت خانه، قیمت مسکن 28 هزار دلار بیشتر از میانگین پیشبینی میشود. اکنون میتوان فرمول را به گونهای تغییر داد که بیش از یک متغیر مستقل وجود داشته باشد. دستور زیر این موضوع را نشان میدهد.
اگر مشابه بالا خلاصه کمترین مربعات معمولی رگرسیون چاپ شود، میتوان اطلاعات مرتبط و متناسب نیاز را دریافت کرد. با نگاه به خروجی، روشن است که بین مساحت خانه و قیمت مسکن رابطه مستقیمی وجود دارد. بهطوری که مقدار t-value بسیار بالا (144.920) و |P>|t صفر درصد است. این یعنی، احتمال اینکه رابطه میان قیمت مسکن و مساحت مسکن شانسی یا به دلیل تغییرات آماری باشد تقریباً صفر است. بهعلاوه، ارتباط میان قیمت مسکن و اندازه آن یک رابطه با اندازه و بزرگی (Magnitude) مناسب است، بهگونهای که به ازای هر 100 فوت مربع اضافه شده به وسعت خانه، قیمت مسکن 28 هزار دلار بیشتر از میانگین پیشبینی میشود. اکنون میتوان فرمول را به گونهای تغییر داد که بیش از یک متغیر مستقل وجود داشته باشد. دستور زیر این موضوع را نشان میدهد.
Reg = ols(‘Dependent variable ~ivar1 + ivar2 + ivar3… + ivarN, dataframe).fit()
print(Reg.summary())
با کمک دستورات زیر تعداد متغیرهای مستقل را افزایش میدهیم:
m = ols(‘price ~ sqft_living + bedrooms + grade + condition’,df).fit()
print (m.summary())
اکنون خروجی به شرحی است که مشاهده میکنید: 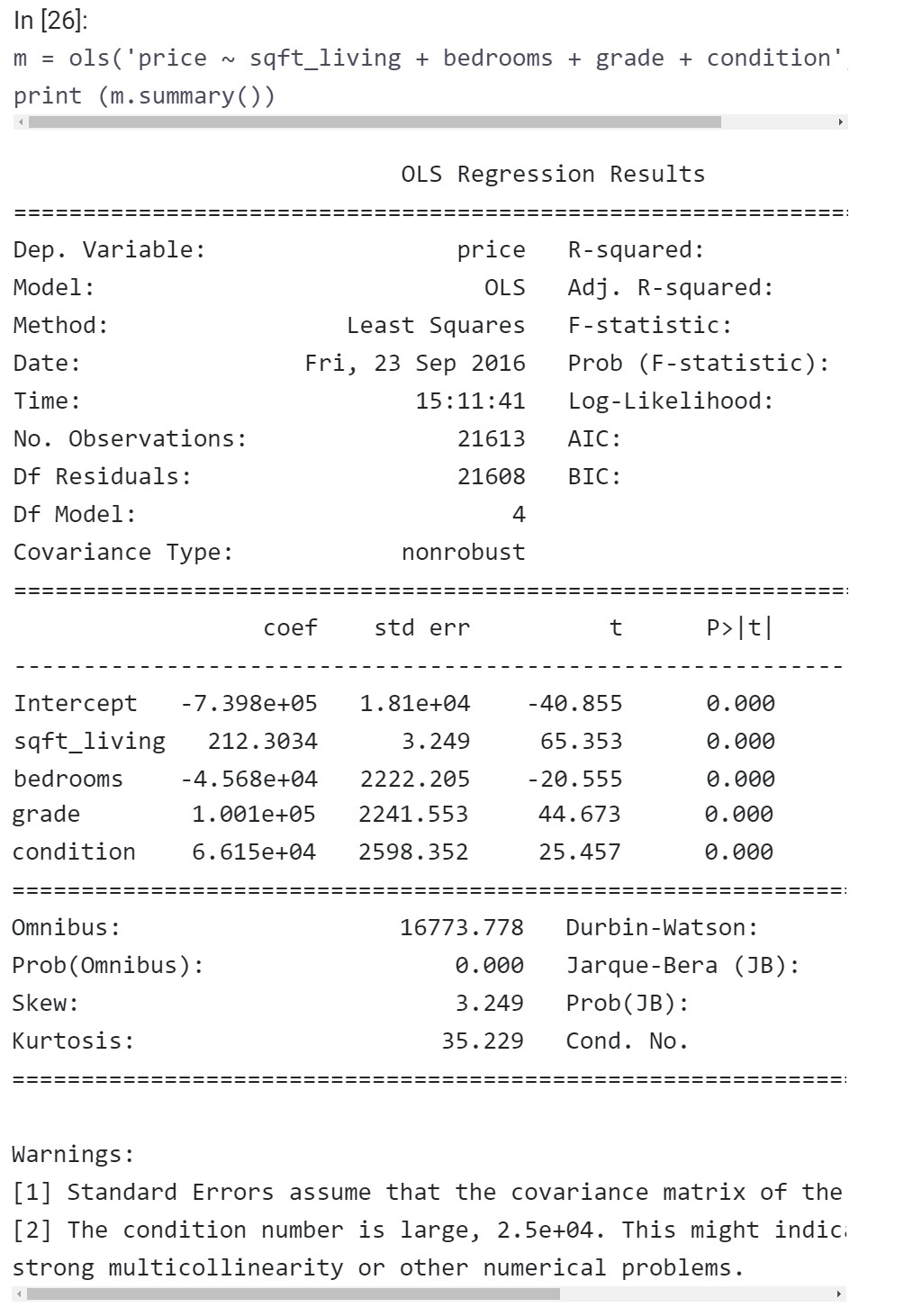 اطلاعاتی که در تصویر بالا مشاهده می کنید خروجی یک رگرسیون خطی چندگانه (Multivariate Linear Regression) است. همانگونه که اشاره کردیم، میتوان از متغیرهای مستقل اضافی مثل تعداد اتاق خوابها (Number Of Bedrooms) استفاده کرد. باید دقت کنید که به واسطه افزایش تعداد متغیرهای مستقل، مدل ارائه شده با مجموعه دادهها مناسبتر است.
اطلاعاتی که در تصویر بالا مشاهده می کنید خروجی یک رگرسیون خطی چندگانه (Multivariate Linear Regression) است. همانگونه که اشاره کردیم، میتوان از متغیرهای مستقل اضافی مثل تعداد اتاق خوابها (Number Of Bedrooms) استفاده کرد. باید دقت کنید که به واسطه افزایش تعداد متغیرهای مستقل، مدل ارائه شده با مجموعه دادهها مناسبتر است.
گام سوم: مصورسازی نتایج رگرسیون
پس از مرحله تحلیل اکتشافی، باید نحوه مصورسازی نتایج مدل رگرسیون را بررسی کنیم. داشتن خلاصه رگرسیون به این دلیل مهم است که با استفاده از آن میتوان مقدار دقت دادهها و مدل رگرسیون را برای فرآیندها پیشبینی کرد.
مصورسازی رگرسیون نیز یک گام مهم برای درک عمیقتر نتایج رگرسیون است، زیرا از طریق به کارگیری روشها و قالبهای بصری به سادگی میتوان کاربرد و عملکرد رگرسیون را درک کرد. برای انجام مصورسازی به کتابخانه Seaborn نیاز داریم. Seaborn یک عملکرد ساده و قابل فهم ارائه میدهد که برای ترسیم خطوط رگرسیون با نمودارهای پراکندگی استفاده میشود. با استفاده از دستور زیر میتوان نمودارهای خطوط رگرسیون با نمودارهای پراکندگی را ایجاد کرد:
sns.jointplot(x=”sqft_living”, y=”price”, data=df, kind = ‘reg’,fit_reg= True, size = 7)
plt.show()
خروجی قطعه کد فوق به صورت زیر است: 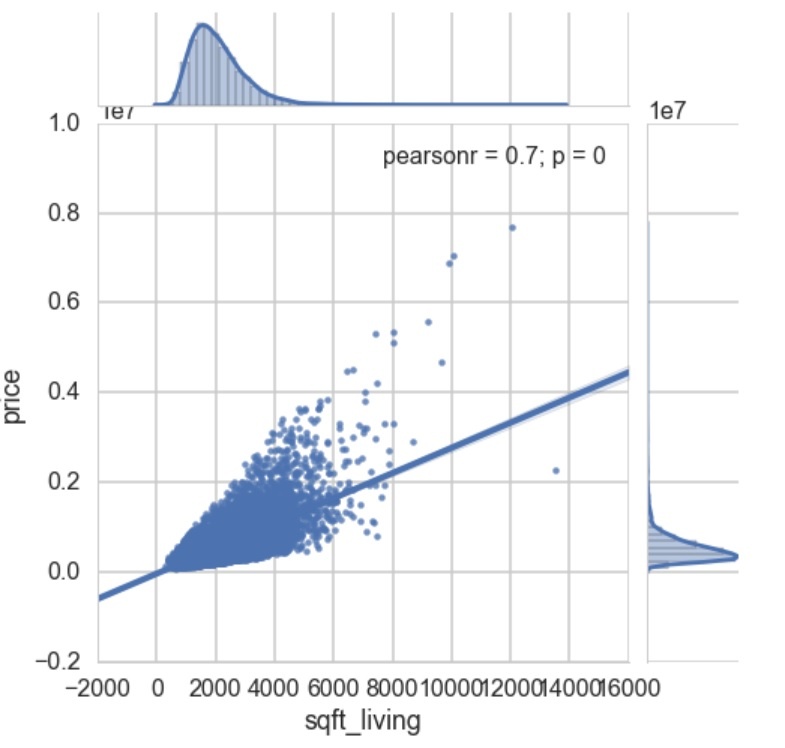 در نهایت ساخت مدل رگرسیون به طور کامل انجام شد. باید دقت کنید در پایتون روشهای مختلفی برای اجرای تحلیل رگرسیون وجود دارد که در این مقاله سادهترین روش بررسی شد.
در نهایت ساخت مدل رگرسیون به طور کامل انجام شد. باید دقت کنید در پایتون روشهای مختلفی برای اجرای تحلیل رگرسیون وجود دارد که در این مقاله سادهترین روش بررسی شد.
کلام آخر
یکی دیگر از نکات مهمی که هنگام دادهکاوی در پایتون باید به آن دقت کنید تحلیل خوشهای است. تحلیل خوشهای (Clustering Analysis) یک روش آماری است که برای گروهبندی اشیا مشابه در دستههای مربوطه استفاده میشود.
اصطلاحاتی مثل تجزیه و تحلیل قطعهبندی (Segmentation Analysis)، تجزیه و تحلیل طبقهبندی (Taxonomy Analysis) یا خوشهبندی (Clustering) همگی به تحلیل خوشهای اشاره دارند.
هدف از اجرای تحلیل خوشهای، مرتبسازی اشیا مختلف یا نقاط داده در گروههای مختلف است. در این حالت اگر دو شی در یک گروه خاص قرار بگیرند یعنی میزان ارتباط بین آن دو شی بالا است. رویکرد تحلیل خوشهای با دیگر روشهای آماری تفاوت دارد، زیرا در بیشتر موارد روش خوشهبندی در شرایطی استفاده میشود که متخصصان برای پایه تحقیقات یک اصل یا واقعیت را به کار نمیگیرند.
روش خوشهبندی در مرحله مقدماتی یا اکتشافی اجرا میشود و برعکس روش تحلیل عاملی (Factor Analysis) تمایزی میان متغیرهای وابسته و مستقل ایجاد نمیکند. این تکنیک به گونهای طراحی شده که ساختارهای دادههای گوناگون را بدون ارائه تفسیر یا توضیحات خاصی پیدا کند.
از مهمترین تکنیکها در این زمینه باید به خوشهبندی سلسله مراتبی (Hierarchical Cluster)، خوشهبندی K میانگین (K-Means Cluster) و خوشهبندی دو مرحلهای (Two-Step Cluster) اشاره کرد.
نویسنده: حمیدرضا تائبی منبع: https://www.springboard.com/blog/data-science/data-mining-python-tutorial/